Dileep George
AGI Research at DeepMind
Entrepreneur, Scientist, and Engineer
Previously Co-founder & CTO at Vicarious AI
I am an engineer, scientist, and entrepreneur working on AI, neuroscience, and robotics. My goals are to understand how the brain works and to build Artificial General Intelligence (AGI). I'm now at DeepMind via acquisition of Vicarious.
I like building teams to pursue challenging goals. I co-founded two companies – Vicarious AI & Numenta. Vicarious was recently acquired by Alphabet: our AI+robotics business merged with Intrinsic, an Alphabet company, and our research team joined DeepMind to accelerate progress toward AGI.
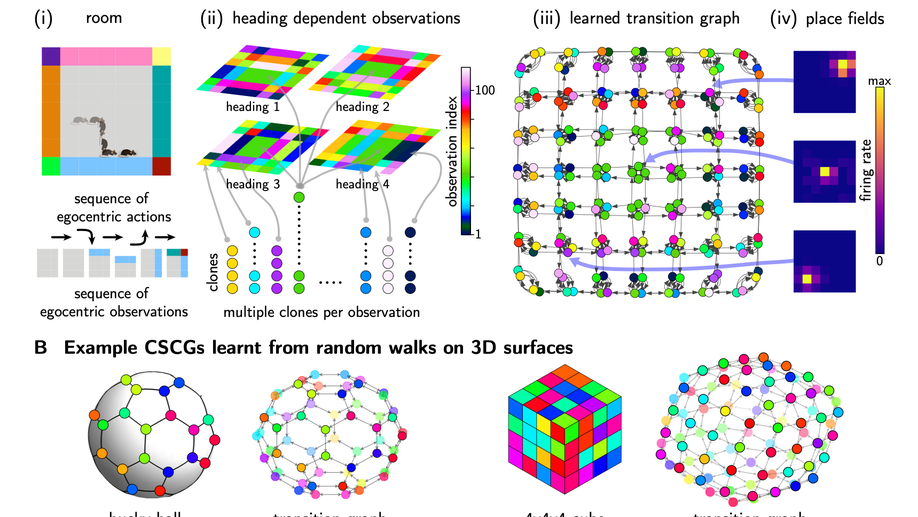
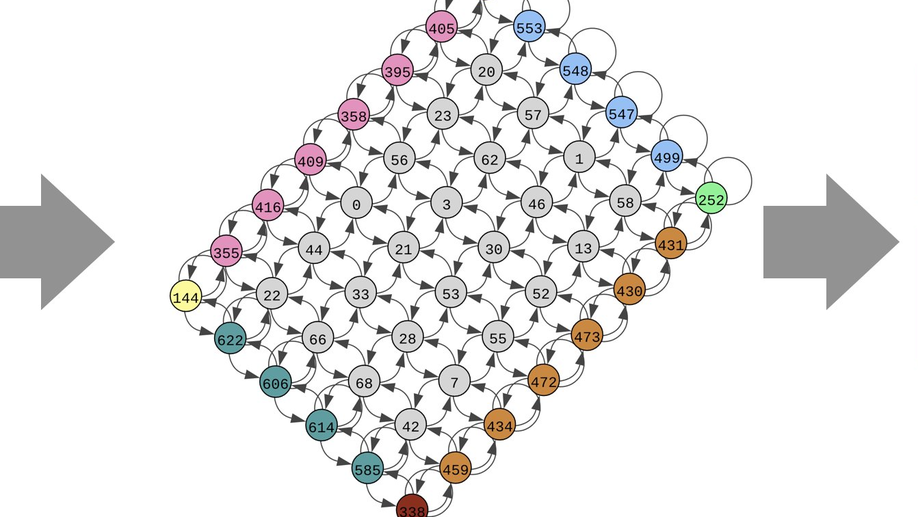
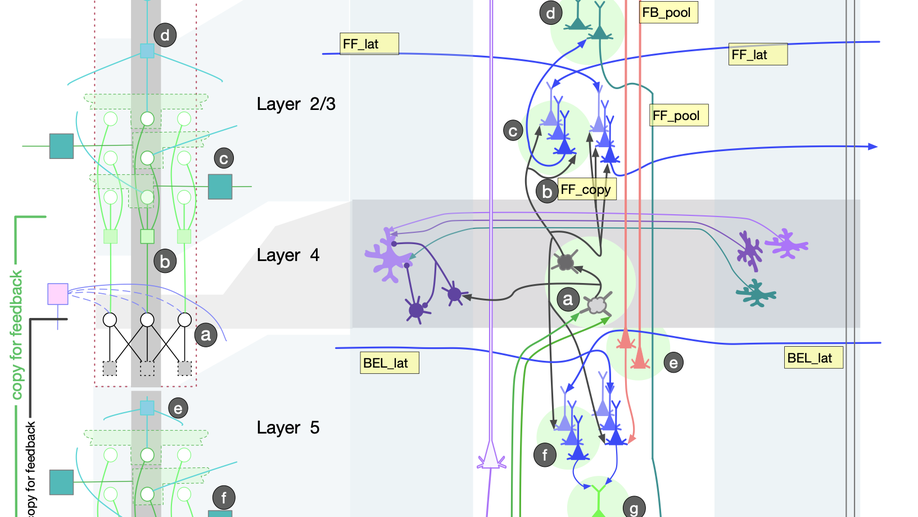
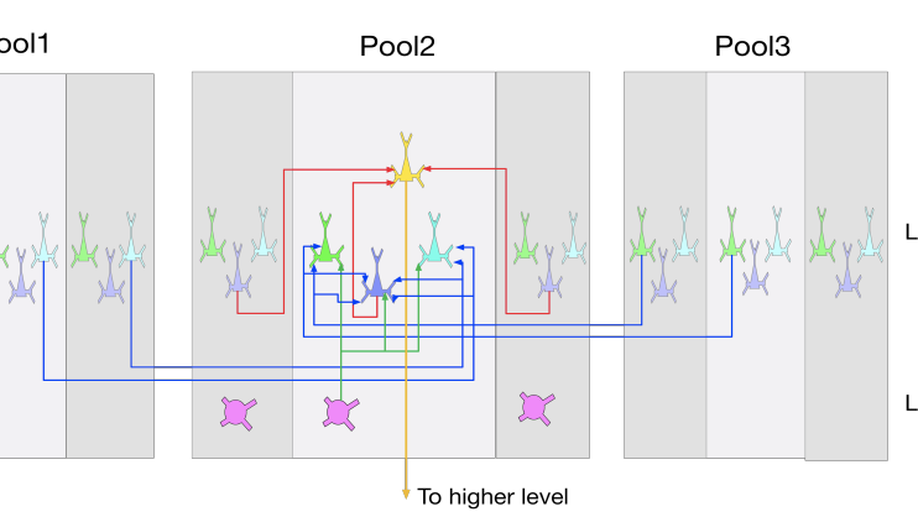
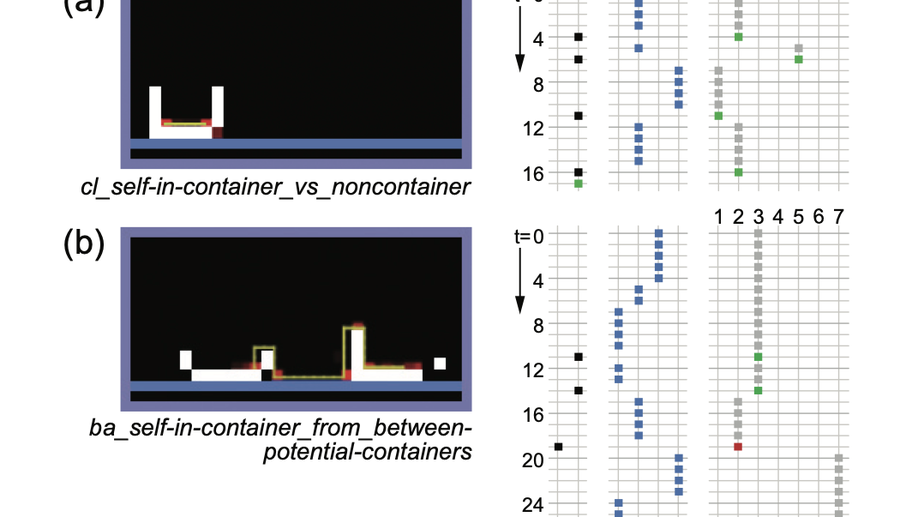
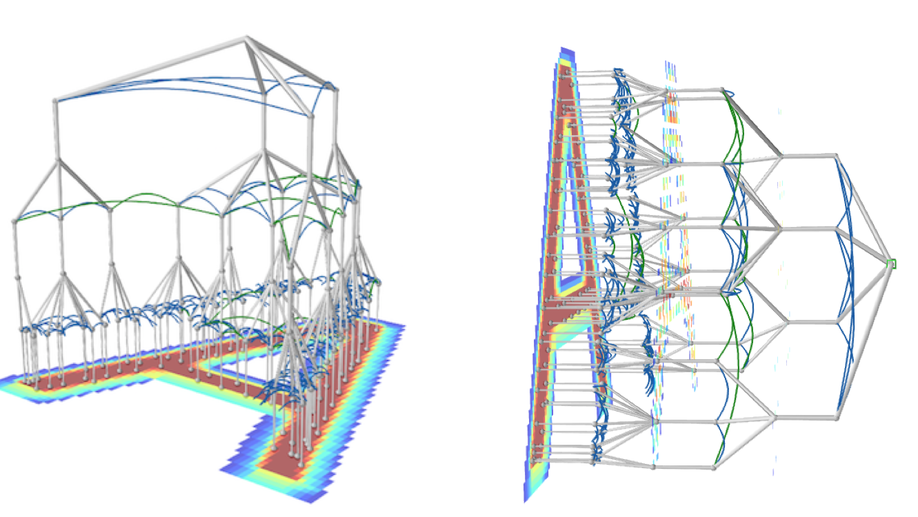
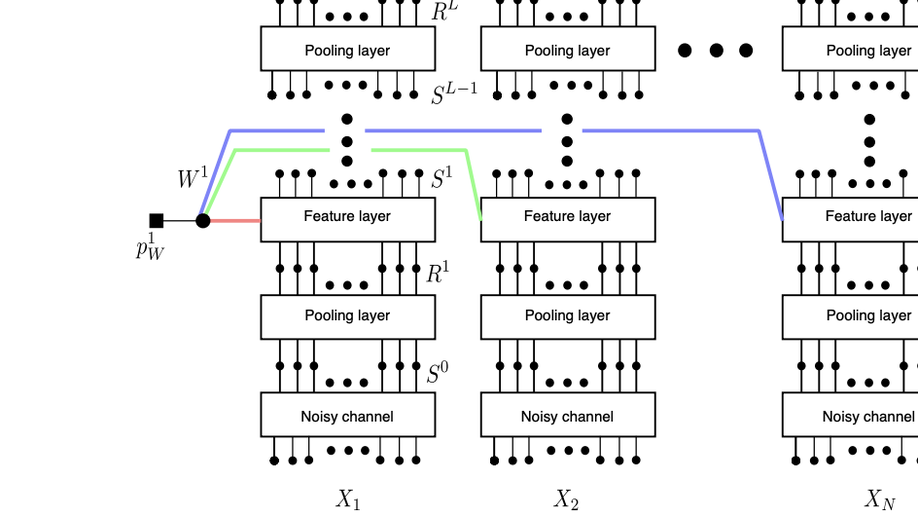
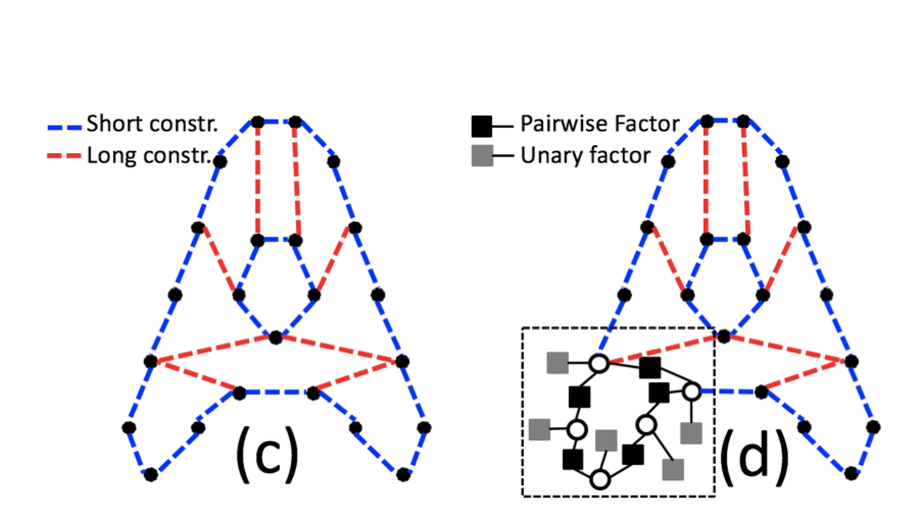
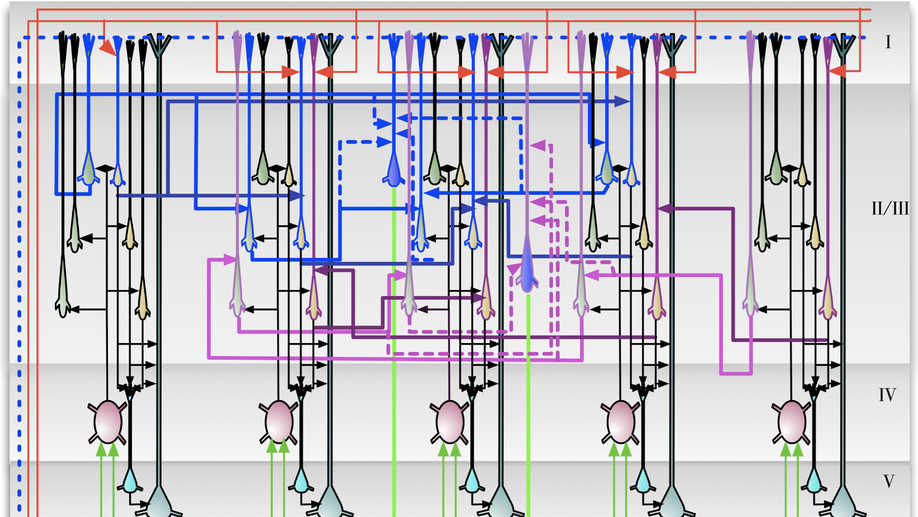
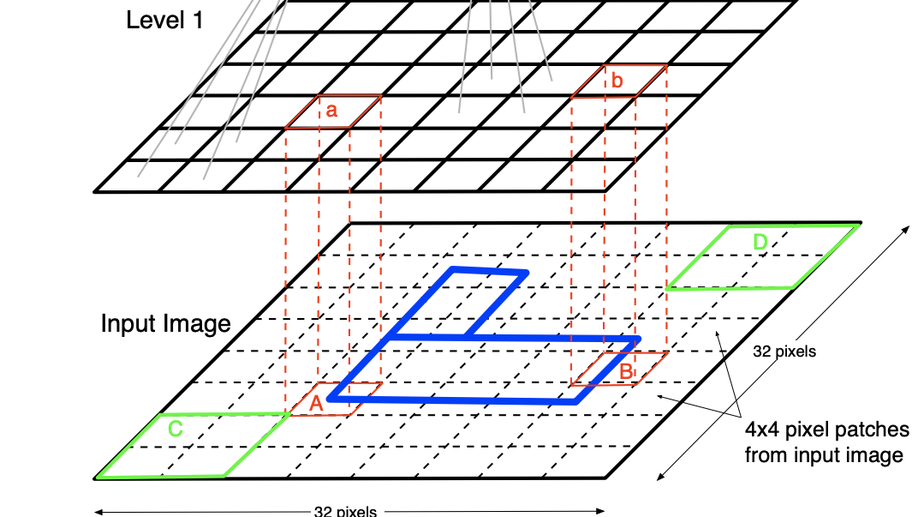
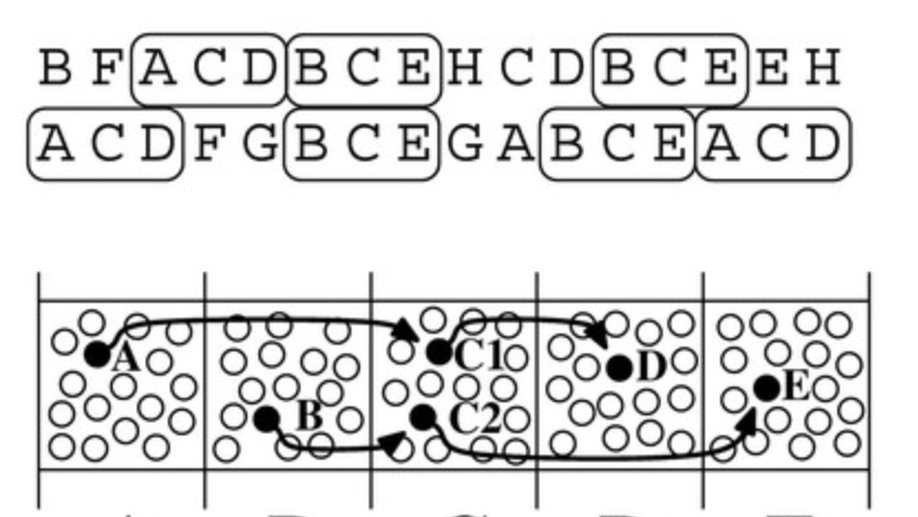
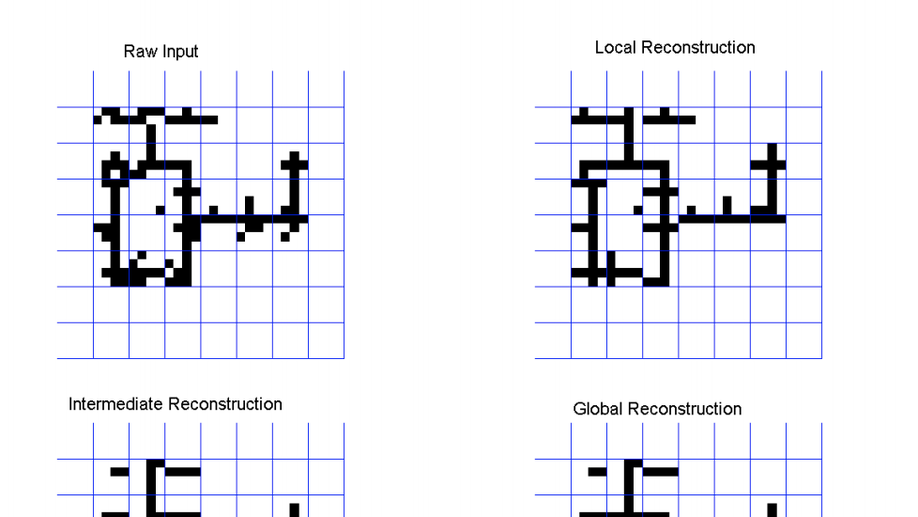
Check out my works on a detailed theoretical model for thalamic and cortical microcorcuits, and place cells as sequence learners for examples of recent progress on understanding the brain.
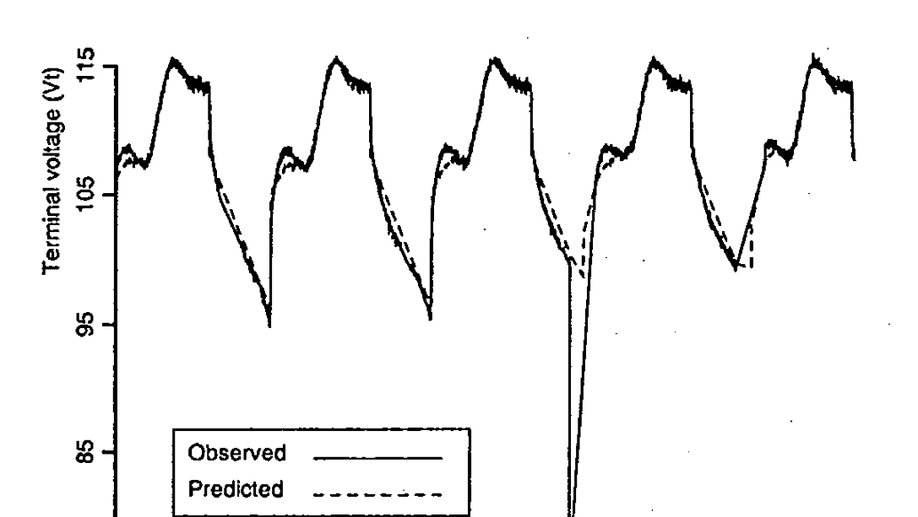
I did my PhD at Stanford University with Dr. Bernard Widrow, a pioneer of neural networks, and co-inventor of LMS gradient descent. During my PhD, I co-founded Numenta with Jeff Hawkins and Donna Dubinsky, and co-developed the ideas behind Hierarchical Temporal Memory.
Interests
- Artificial Intelligence
- Neuroscience and cognitive science
- Robotics
- Entreprenuership
Education
-
PhD in Electrical Engineering
Stanford University
-
MS in Electrical Engineering
Stanford University
-
BTech in Electrical Engineering
IIT Bombay